


传统的目标检测算法由于泛化性和稳健性较差,并不适用于复杂的露天矿区场景(Wang et al.,2019)。随着GPU硬件技术的飞速进步,基于深度学习的目标检测算法因具有检测结果精度高和处理速度快等优点而在自动驾驶领域得到了广泛应用(Pathak et al.,2018;王京华等,2021)。目前主流的目标检测算法包括R-CNN系列的双阶段算法(Girshick et al.,2014;Girshick,2015;Ren et al.,2016)和YOLO系列的单阶段算法(Redmon et al.,2015,2018;Bochkovskiy et al.,2020;Zhu et al.,2021),均在露天矿区障碍物检测中得到了应用。秦学斌等(2023)针对光照不均匀和遮挡等场景,提出了一种基于16线激光雷达与Realsense D435深度相机融合的煤矿自动驾驶矿卡车前障碍物检测方法,解决了传统障碍物检测方法存在的漏检和实时性差的问题。阮顺领等(2021)根据露天矿区存在的道路坑洼和塌陷等负向障碍物,建立了基于机器视觉的轻量化目标检测模型,能够有效识别负障碍物。秦晓辉等(2023)针对目前实地部署的商用采矿无人系统难以准确识别障碍物类型的问题,提出了一种基于改进YOLOv5的露天矿山目标检测方法,在保证实时性的前提下有效提高了YOLOv5的检测精度。上述露天矿区障碍物检测算法在白天场景下得到了较好的应用,并取得一定成果,但针对复杂矿区环境仍存在以下局限性:(1)露天矿区矿卡车载摄像头易受粉尘干扰,数据样本间质量差异大,导致检测识别困难;(2)矿区障碍物的检测局限于特定的单一白天场景,并未同时考虑夜间场景下障碍物检测问题;(3)高精度检测和识别模型的运行成本较高,计算资源消耗大。在露天矿区特殊场景下,如何以低成本实现高效的障碍物检测仍需进一步研究。
针对上述问题,本文采集了露天矿区场景下受粉尘干扰和光线影响的白天与夜间车辆行驶数据。改进YOLOv8网络,在主干网络中引入C2fCA模块,减轻噪声带来的干扰,提高了模型的特征提取能力;重构模型的Neck端减轻复杂度,平衡检测的准确性和实时性,实现了检测器更高的计算成本效益;优化目标边界框损失函数,提高模型的泛化能力并加速收敛。使用白天与夜间车辆行驶的数据集进行障碍物检测试验,达到了障碍物检测精度高、计算成本低和实时性的要求。
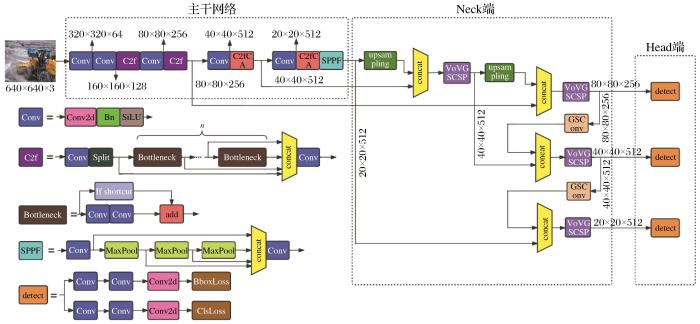
1 露天矿区行车障碍物检测算法设计
1.1 模型结构
在露天矿区工程应用中,网络模型部署所使用的计算设备通常计算能力有限。为了同时保证检测精度和检测速度,以YOLOv8架构为基础,针对现有目标检测算法的缺陷并结合露天矿区复杂的环境特点,提出了障碍物检测模型结构(图1)。在主干网络,提出了具有共享权重和上下文感知权重的C2fCA模块结构替换P4层和P5层的C2f结构,更好地处理由于噪声影响导致图像中不同位置之间依赖关系受到割裂的问题。在颈部网络中采用轻量级卷积技术GSConv和VoV-GSCSP模块减轻模型的复杂性,实现高性能检测。在头部分类预测阶段,使用WIoU损失函数,提高了模型的泛化能力和检测精度。
图 1
1.2 重构主干网C2f模块处理图像位置关系
在露天矿区,由于无人驾驶矿卡车的车载摄像头经常受到扬尘和颗粒物等粉尘的遮挡,加上空气中弥漫着大量尘土,导致摄像头捕捉到的图像模糊;夜间矿区照明设施不充足,光照条件较差,严重影响图像的清晰度和辨识度。这些因素导致卷积神经网络模型在提取图像特征时产生大量噪声,破坏图像不同位置间的依赖关系,降低障碍物检测和识别的准确率。处理好图像不同位置间的依赖关系,有助于计算机视觉系统更好地理解图像中的物体,提高目标检测和识别效果。
本研究使用的CloFormer网络(Fan et al.,2023)通过引用注意力机制和卷积运算相结合的AttnConv模块[图2(a)],使用共享权重和上下文感知权重,能够更好地处理图像中不同位置之间的关系。因此,本文通过在YOLOv8的主干网络中加入AttnConv模块,形成C2fCA模块[图2(b)],替换主干网络中后2个C2f模块。首先,C2fCA模块中卷积核权重是共享的,即对于不同位置的输入特征,使用相同的卷积核权重进行计算,使得整个图像学习到通用的特征,增强对不同位置之间关系的建模能力;同时,共享权重保证了在图像不同位置使用相同的特征提取模式,从而使得不同位置之间的特征表示更加一致。其次,C2fCA模块使用注意力机制,根据输入特征的上下文信息计算上下文感知权重,在不同位置处对特征进行不同程度的加权,使得模型更加关注图像中不同位置的重要性。
图2

通过结合共享权重和上下文感知权重,C2fCA模块在处理图像时能够更加灵活地捕捉不同位置之间的关系,使得模型更具有稳健性和泛化能力,不仅克服了露天矿区行车车载摄像头受粉尘干扰和夜间光线不足等因素的影响,而且解决了噪声造成的图像位置割裂和依赖关系问题,提高了障碍物检测精度。
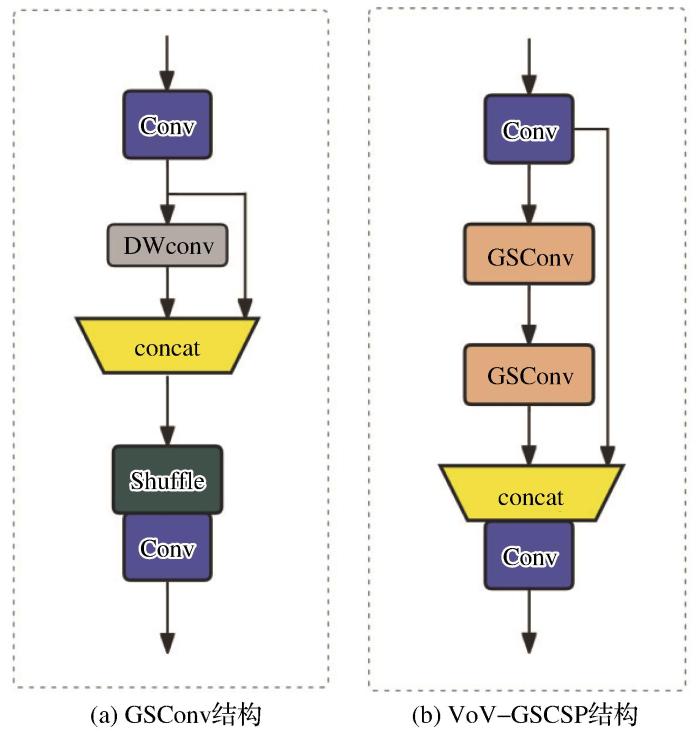
1.3 重构Neck端减轻模型复杂度
露天矿区无人驾驶矿卡车在作业时车载摄像头要处理大量数据,使用原始的YOLOv8模型进行障碍物检测和识别,将会产生较高的计算资源成本,对于露天矿区车载边缘计算平台如何高效地利用计算资源和提供实时准确的数据具有重要意义。
本研究中使用GSConv新型卷积方式(Li et al.,2022)[图3(a)],该卷积方式的原理是使用均匀混合(Shuffle)操作,将标准卷积生成的信息渗透到深度可分离卷积生成的信息中,使用较低的时间损耗尽可能保留通道之间的信息交互,从而很好地减轻模型的复杂度。同时,使用VoV-GSCSP模块[图3(b)]提高模型的学习能力。重构后的Neck端使用GSConv代替普通卷积操作,VoV-GSCSP模块代替原来的C2f模块,不仅降低了模型的复杂度,缩短了推理时间,而且保证了模型的准确型,相比原有的模型参数降低了约7%,降低了检测器的计算成本。
图3
1.4 优化损失函数
YOLOv8模型使用CIoU损失函数(Zheng et al.,2020)计算边界框的回归损失,CIoU损失函数的计算公式为
式中:
式中:w为预测框的宽;h为预测框的高;wgt为真实框的宽;hgt为真实框的高。
在边界框回归中,CIoU作为损失函数对宽高比的定义并不是很清晰,其宽高比不能代表预测框与真实框之间的宽高比。当实际数据较复杂时,模型效果会变差。如图4所示,露天矿区在粉尘干扰严重和摄像头被尘土遮挡的情况下,特别是在夜间光线不足的情况下,数据质量间存在较大的差距。低质量数据会影响模型在训练中的特征学习能力,降低模型的泛化能力和检测精度。考虑到以上问题,本文将YOLOv8网络模型的边框损失函数由CIoU替换为WIoU(Tong et al.,2023)。
图4

基于动态非单调聚焦机制的WIoU损失函数,可以缓解瞄框标注质量对网络模型整体收敛速度和定位精度的影响,解决质量较好与质量较差样本间的边界框回归平衡问题,提高模型的泛化能力并加速收敛。WIoU损失函数的计算公式为
式中:
2 露天矿区行车障碍物数据集构建
本文采集矿卡车车载摄像头白天与夜间场景下的前、左和右视角的RGB 图像,图像分辨率为1 200 pixel×1 080 pixel,在输入网络时将图像大小调整为640 pixel×640 pixel。原始数据集共有2 952张图像(白天2 120张和夜间832张),包含5个类别,分别是矿区运载卡车(truck)、矿区挖掘机(excavator)、其他车辆(car)、行人(person)和在夜间行车时高亮度的车灯(carlight),将这5个类别作为主要检测目标,图5所示为5个类别的实例。
图5

本研究对白天和夜间2个场景分别进行行车障碍物检测试验。由于数据集中图像数量过少,导致网络难以达到良好的拟合状态,因此通过数据扩增的方法来丰富数据的多样性,提高模型的泛化能力。通过采取改变亮度、灰度化处理和增强对比度等扩增方法对原始图像进行处理,使样本扩增为原来的3倍。该数据集包含12 465个矩形框实例,分类统计结果如图6所示,其中白天与夜间的矩形框数量分别对应不同类别的实例数量。
图6
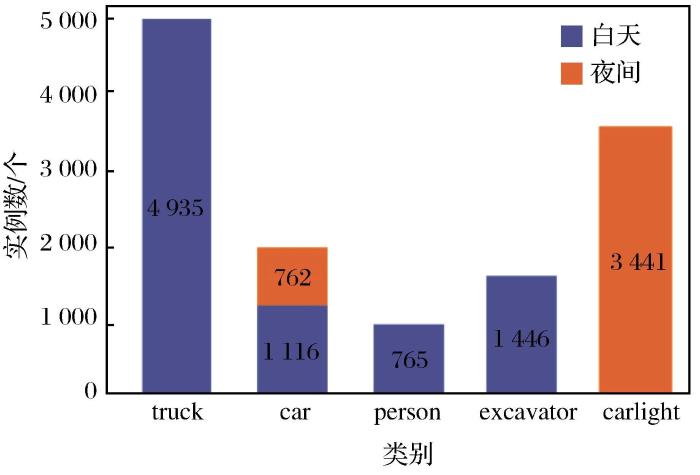
图6
数据集不同类别的实例分布
Fig.6
Example distribution of different categories of data sets
3 试验验证
本研究将白天与夜间所构建的数据集分别按照7∶1∶2划分为训练集、验证集和测试集进行试验。试验环境配置如下:Linux Ubuntu 18.04 LTS 的操作系统,IntelⒸCoreTM i7-7800X CPU,24 GB的显存NVIDIA GeForce RTX3090 Ti GPU,CUDA 11.1,Pytorch 1.10.0。
在所有试验中,模型的输入分辨率为640 pixel×640 pixel,超参数设置批大小(batch size)为16,训练周期(epochs)经试验后分别确定为200(白天)和150(夜间),初始学习率(learning rate)为0.01,优化器为SGD(Stochastic Gradient Descent)。
3.1 评价指标
本试验采用平均精度均值(mean Average Precision,mAP)来评价模型的准确性,mAP50的含义为IOU阈值为0.5时的平均精度均值。mAP计算公式为
式中:
采用每秒传输帧数(Frames Per Second,FPS),计算网络每秒可以处理(检测)多少帧(多少张图片),计算公式为
式中:
3.2 改进方法效果对比
前文提出基于YOLOv8n的改进结构,包括对主干网C2f模块、Neck端和损失函数的改进,通过以下试验来验证改进方法的有效性。
(1)主干网C2f模块改进试验
改进YOLOv8n的主干网中的C2f模块,本研究将后2个C2f模块替换为C2fCA模块。试验结果表明,替换后模型的计算量相较YOLOv8n增加了0.2 GFLOPs,参数量增加了0.12 M,但针对白天和夜间场景下障碍物检测的mAP50分别提高了1.3%和2.5%(表1)。
表1 主干网改进后性能对比
Table 1
| 模型 | 计算量 /GFLOPs | 参数量/M | mAP50/% | |
|---|---|---|---|---|
| 白天 | 夜间 | |||
| YOLOv8n(Baseline) | 8.2 | 3.01 | 95.7 | 92.5 |
| +2 C2fCA | 8.4 | 3.13 | 97.0 | 95.0 |
| +1 C2fCA对照 | 8.2 | 3.09 | 95.1 | 94.3 |
| +3 C2fCA对照 | 8.5 | 3.15 | 96.0 | 95.4 |
| +4 C2fCA对照 | 8.6 | 3.15 | 94.5 | 95.0 |
为了进一步验证C2fCA模块的有效性,开展了3组对照试验,分别替换不同数量的C2fCA模块。从表1可以看出,C2fCA模块对夜间障碍物检测效果好一些,但过多的使用C2fCA模块会导致网络层数增加,计算资源消耗增大。因此本研究将后2个C2f模块替换为C2fCA模块。
(2)Neck端改进试验
Neck端使用新的卷积方式GSConv和VoV-GSCSP模块构成了new-Neck端。表2为改进后模型的性能参数,相比原YOLOv8n模型,改进后模型的计算量和参数量分别降低了约10%和7%。同时,改进后的模型计算速度是87 FPS,可达到实时的检测速度,mAP50在白天和夜间场景下分别提高了1.4%和1.2%。
表2 Neck端改进后性能对比
Table 2
| 模型 | 计算量 /GFLOPs | 参数量/M | mAP50/% | 计算速度 /FPS | |
|---|---|---|---|---|---|
| 白天 | 夜间 | ||||
| YOLOv8n(Baseline) | 8.2 | 3.01 | 95.7 | 92.5 | 80 |
| +new-Neck | 7.4 | 2.80 | 97.1 | 93.7 | 87 |
(3)损失函数改进试验
表3 损失函数改进后性能对比
Table 3
| 模型 | 计算量 /GFLOPs | 参数量/M | mAP50/% | |
|---|---|---|---|---|
| 白天 | 夜间 | |||
| YOLOv8n(Baseline) | 8.2 | 3.01 | 95.7 | 92.5 |
| +WIoU | 8.2 | 3.01 | 96.8 | 94.2 |
| +2 C2fCA+WIoU | 8.4 | 3.13 | 97.2 | 95.0 |
| +new-Neck+WIoU | 7.4 | 2.80 | 97.0 | 94.6 |
3.3 消融试验
表 4 消融试验结果
Table 4
| 模型 | C2fCA | new-Neck | WIoU | 计算量 /GFLOPs | 参数量 /M | mAP50/% | 检测速度/FPS | |
|---|---|---|---|---|---|---|---|---|
| 白天 | 夜间 | |||||||
| YOLOv8n(Baseline) | - | - | - | 8.2 | 3.01 | 95.7 | 92.5 | 80 |
| N1 | √ | - | - | 8.4 | 3.13 | 97.0 | 95.0 | 61 |
| N2 | - | √ | - | 7.4 | 2.80 | 97.1 | 93.7 | 87 |
| N3 | - | - | √ | 8.2 | 3.01 | 96.8 | 94.2 | 80 |
| N4 | √ | √ | - | 7.5 | 2.92 | 96.3 | 94.7 | 69 |
| YOLOv8n-Enhanced | √ | √ | √ | 7.5 | 2.92 | 97.5 | 95.1 | 69 |
图7
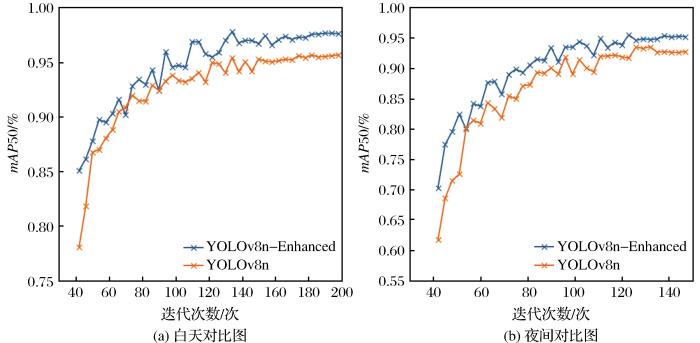
图7
模型改进前后mAP50曲线对比
Fig.7
Comparison of the mAP50 curves before and after model improvement
图8

图8
改进前后算法效果对比
Fig.8
Comparison of algorithm effects before and after the improvement
表5所示为改进模型YOLOv8n-Enhanced与其他目标检测模型[包括Faster R-CNN、SSD(Liu et al.,2016)、YOLOv5和YOLOv7]在相同试验条件和数据集下进行障碍物检测的性能对比结果。由表5可知:本文改进算法在白天和夜间的检测精度mAP50分别达到97.5%和95.1%,检测速度为69 FPS,远高于其他4种目标检测模型,且参数量仅为2.92 M。在露天矿区无人驾驶场景中,对于高精度检测和实时检测的需求,本文提出的改进算法表现最优。
表5 不同模型检测性能对比
Table 5
| 模型 | 参数量 /M | mAP50/% | 检测速度 /FPS | |
|---|---|---|---|---|
| 白天 | 夜间 | |||
| YOLOv8n-Enhanced | 2.92 | 97.5 | 95.1 | 69 |
| Faster-Rcnn | 40 | 83.0 | 53.2 | 28 |
| SSD300 | 26.2 | 64.3 | 52.4 | 34 |
| YOLOv5s | 7.07 | 93.5 | 91.5 | 65 |
| YOLOv7-tiny | 6.03 | 95.0 | 92.3 | 54 |
4 结论
针对露天矿区行车障碍物检测容易受扬尘和颗粒物等粉尘噪声的干扰,难以准确识别障碍物,尤其是对夜间障碍物检测的问题,本研究提出了YOLOv8n-Enhanced露天矿区行车障碍物检测模型。该模型采用C2fCA模块解决粉尘噪声问题,增强图像不同位置之间的依赖关系,提高了模型的检测准确性。
同时,为实现露天矿区无人驾驶检测器更高的计算成本效益,重构模型的Neck端,平衡模型的准确性和实时性。针对样本间质量差异大的边界框回归平衡问题,采用WIoU损失函数,提高了模型的泛化能力并加速收敛。试验结果表明,模型在白天和夜间场景下均取得良好的检测性能。尽管本研究提出的方法在一定程度上提高了露天矿特殊场景下障碍物的检测精度,并满足实时检测的要求,但当前工作仍无法覆盖不同情况的露天矿区,后续将继续丰富数据集,并在不同环境下的露天矿区中进行测试和优化。
http://www.goldsci.ac.cn/article/2024/1005-2518/1005-2518-2024-32-2-345.shtml
参考文献
YOLOv4:Optimal speed and accuracy of object detection
[J].
Research on Mine Roadway Obstacle Detection Based on Infrafed Binocular Vision
[D].
Rethinking local perception in lightweight vision transformer
[J].
Fast R-CNN
[C]//
Rich feature hierarchies for accurate object detection and semantic segmentation
[C]//
Slim-neck by GSConv:A better design paradigm of detector architectures for autonomous vehicles
[J].
SSD:Single Shot MultiBox Detector
[M]//
Research on Nighttime Road Obstacle Image Semantic Segmentation Based on Attention Mechanism
[D].
Application of deep learning for object detection
[J].
Object detection method for open-pit mine based on improved YOLOv5
[J].
Research on front obstacle detection algorithm for autonomous mining trucks in open-pit coal mines
[J/OL].
You only look once:Unified,real-time object detection
[C]//
YOLOv3:An incremental improvement
[J].
Faster R-CNN:Towards real time object detection with region proposal networks
[J].
Road obstacle detection in open-pit mining area based on two-way feature fusion
[J].
Road negative obstacle detection in open-pit mining areas with multi-scale feature fusion
[J].
Wise-IoU:Bounding box regression loss with dynamic focusing mechanism
[J].
A comparative study of state-of-the-art deep learning algorithms for vehicle detection
[J].
Obstacle detection technology of mine electric locomotive driverless based on computer vision technology
[J].
Nighttime vehicle object detection algorithm for unmanned driving based on improved YOLOv5s
[J].
Research on the current situation and development trend of unmanned driving transportation technology in open-pit mines
[J].
Distance-IoU loss:Faster and better learning for bounding box regression
[C]//
TPH-YOLOv5:Improved YOLOv5 based on transformer prediction head for Object detection on drone-captured scenarios
[C]//DOI:10.1109/ICCVW 54120.2021.00312 [本文引用: 1]
基于红外双目视觉的矿井巷道障碍检测研究
[D].
融合注意力机制的夜间道路障碍物图像语义分割方法研究
[D].
基于改进YOLOv5的露天矿山目标检测方法
[J].
露天煤矿自动驾驶矿卡车前障碍物检测算法研究
[J/OL].
基于双向特征融合的露天矿区道路障碍检测
[J].
多尺度特征融合的露天矿区道路负障碍检测
[J].
基于计算机视觉技术的矿井电机车无人驾驶障碍物检测技术
[J].
基于改进YOLOv5s的无人驾驶夜间车辆目标检测算法
[J].
露天矿山无人驾驶运输技术现状及发展趋势研究
[J].


 甘公网安备 62010202000672号
甘公网安备 62010202000672号{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}