


有轨电机车是矿山主要的运输方式之一。地下矿无人驾驶电机车的实现能够将矿山运输系统整合为一个可以统筹调度的有机整体,实现减员增效,降低生产成本。同时,地下矿电机车运输环境较为特殊,实际驾驶过程中遇到的障碍物并不多,但行驶区域不可避免地会出现维修工人、掉落的大块矿石和电机车等,因此,及时对电机车前方障碍物作出响应十分重要。
快速精准地识别并定位车辆前方障碍物是无人驾驶电机车最为关键的技术之一。目前障碍物检测方法从大的方向可以分为2种类型:一种是基于激光雷达的检测方法(Dewan et al.,2016),另一种是基于视觉感知的检测方法(Ruder et al.,2003)。基于激光雷达的方法具有能够分辨障碍物细节、精准测距以及不受光线条件的影响等优点。谢德胜等(2018)利用激光雷达对无人车障碍物进行检测和跟踪,实现了对动态障碍物的跟踪;王新竹等(2016)将激光雷达获得的点云信息以矩阵形式表示为深度图像,通过聚类和建立线性模型,减小斜坡对障碍物检测的影响;娄新雨等(2019)将地图分离为路面、障碍物和悬挂物,提高了聚类的精确率。然而,基于激光雷达技术的检测方法处理过程复杂且价格昂贵,例如Velodyne64线激光雷达售价高达60万元(娄新雨等,2019)。相比之下,基于视觉感知技术的检测方法成本较低,同时由于该方法从人类视觉方向解析环境信息,过程更容易被人类理解。宋怀波等(2011)提出了将最小错误率贝叶斯决策与Hough直线变换结合的方法,并对图像进行2次分割,根据分割后的路面区域直方图信息,完成对非结构化道路路面障碍物的识别;同磊等(2012)提出了一种基于移动车载摄像机检测轨间异物的方法,使用尺度信息和颜色索引等特征参数结合支持向量机(SVM)对可疑异物进行分类和辨识; Güzel et al.(2013)将基于外观的障碍物检测方法集成到基于光流的导航系统中,融合2种方法检测结果;刘文淇(2016)针对铁路线路是否被列车占用,设计了基于深度神经网络的检测算法,可以长期在线监测。
传统计算机视觉方法对物体分类时需要大量的特征参数,另外,在对图像进行中值滤波降噪及灰度等处理后,丢失了物体的颜色纹理等信息,对障碍物的分类造成了很大的影响。目前,基于深度学习的物体检测技术已经有了很大的发展(Liu et al.,2018)。为了取得最好的检测效果,试验选取了当前深度学习目标检测领域2种主流架构中最具代表性的成果,双阶段RCNN系列最新成果Mask R-CNN(He et al.,2020)和单阶段YOLO(Redmon et al.,2016)系列最新成果YOLOv3(Redmon et al.,2017)进行对比。最后,考虑到地下矿特有的场景以及对检测实时性的要求,提出了一种基于传统计算机视觉和深度学习YOLOv3算法的地下矿无人驾驶电机车障碍物智能化检测技术。
1 电机车障碍物智能化检测方法
1.1 障碍物智能化检测技术架构
障碍物智能化检测技术通过电机车头部车载相机获取前方视频信息,识别确定前方有效检测区域内障碍物类别和距离,给出提示信息,具体技术路线如图1所示。
图1
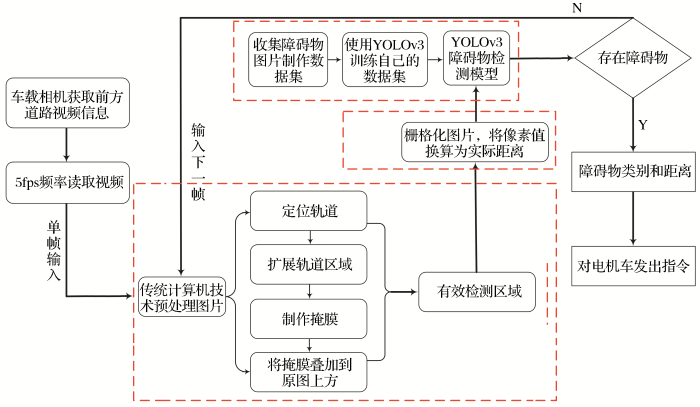
基于传统计算机视觉技术和深度学习模型YOLOv3的地下矿无人驾驶电机车障碍物智能化检测技术主要由4个部分构成。第一,选择YOLOv3模型训练数据集,获得障碍物检测模型;第二,使用传统计算机视觉技术定位轨道并提取有效障碍物检测区域;第三,网格化图片,将像素坐标信息换算为实际距离信息;第四,将处理过的图片放入障碍物检测模型,得到检测结果,根据结果对电机车作出相应指令,从而实现障碍物智能化检测。
1.2 基于YOLOv3的障碍物检测
快速准确识别障碍物是无人驾驶电机车障碍物智能化检测的重点和难点。Redmon et al.(2017)试验研究表明,使用YOLOv3模型对多种障碍物进行分类,在精度上可以和当前最先进的分类器相媲美,速度是其他模型的3~4倍。对当前这2种比较流行的检测网络进行了对比试验,结果如表1所示。
表1 YOLOv3和Mask R-CNN试验结果对比
Table 1
| 模型名称 | 平均单张测试时间/s | 平均精确率MAP/% |
|---|---|---|
| YOLOv3 | 0.02 | 93.2 |
| Mask R-CNN | 0.11 | 94.5 |
综合考虑精确率确率和实时性,本文选用YOLOv3作为障碍物分类模型。
(1)基于YOLOv3的障碍物检测网络模型。如图2所示,基于YOLOv3的轨道障碍物检测模型包含2个部分:①主干网络。主干网络是共享的卷积网络,用于特征提取,选用darknet-53作为轨道障碍物检测的主干网络,darknet-53借鉴了残差网络的做法(He et al.,2016),包含53个卷积层。②多尺度特征检测对象。输入416 pixel×416 pixel的图像经过5次步长为2的卷积(25倍下采样),得到13 pixel×13 pixel的特征图,进行检测,同时进行一次上采样和经过4次步长为2的卷积后的特征图融合,得到26 pixel×26 pixel的特征图,进行检测,同时再进行一次上采样和经过3次步长为2的卷积后的特征图融合,得到52 pixel×52 pixel的特征图,进行检测。使用13∶26∶52 这3种不同尺度的特征图可以满足对尺寸差异很大的石块、人和电机车等目标进行检测。
图2
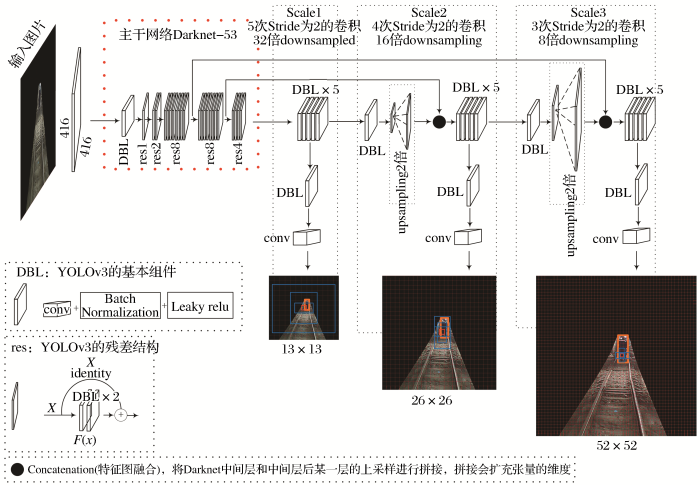
图2
基于YOLOv3的轨道障碍物检测模型结构
Fig.2
Structure of track obstacle detection model based on YOLOv3
特别地,YOLOv3采用多个规模融合的方式进行预测,加强了算法对小目标检测的精确度。在YOLOv3中采用类似FPN(Lin et al.,2017)(Feature Pyramid Networks)的上采样和融合做法(最后融合了3个规模,3个规模的大小分别是13 pixel×13 pixel,26 pixel×26 pixel和52 pixel×52 pixel),在多个规模的特征图上进行检测,对于小目标检测效果提升明显。
(2)基于迁移学习和YOLOv3的障碍物检测流程。为了更快地使网络收敛以提高数据集较少时的训练效率,使用迁移学习的思想(庄福振等,2015),在Imagenet数据集(Deng et al.,2009)上预训练好的模型参数(darknet53.conv.74)基础上训练自己的数据集。结合制作好的轨道障碍物数据集对整个模型进行微调,获得电机车轨道障碍物检测模型。基于YOLOv3的电机车轨道障碍物检测流程如下:
①输入图片进入Darknet-53进行特征提取。
②进行5次步长为2的卷积下采样,每次卷积后都要进入残差组件进行障碍物特征提取。
③原图416 pixel×416 pixel经卷积5次后,得到(416/25)×(416/25)即13 pixel×13 pixel的特征图。
④13 pixel×13 pixel的特征图上每个网格使用3种尺寸(116 pixel×90 pixel,156 pixel×198 pixel,373 pixel×326 pixel)的锚框检测,共13×13×3=507个候选区域。
⑤13 pixel×13 pixel的特征图经过一次上采样,扩大为26 pixel×26 pixel,然后和前面经过4次卷积(416/24)×(416/24)的特征图进行特征融合,得到26 pixel×26 pixel的特征图。
⑥同第④步类似,此时的锚框3种尺寸为30pixel×61 pixel、62 pixel×45 pixel和59 pixel×119 pixel,共26×26×3=2 028个候选区域。
⑦26 pixel×26 pixel的特征图经过一次上采样,扩大为52 pixel×52 pixel,然后和前面经过3次卷积(416/23)×(416/23)的特征图进行特征融合,得到52 pixel×52 pixel的特征图。
⑧同第⑥步类似,此时的锚框3种尺寸为10pixel×13 pixel、16 pixel×30 pixel和33 pixel×23 pixel,共52×52×3=8 112个候选区域。
⑨对于一个416 pixel×416 pixel的输入图像,在每个尺度的特征图的每个网格设置3个先验框,共有候选区域(13×13×3)+(26×26×3)+(52×52×3)=10 647个。
⑩使用逻辑回归对所有的候选区域进行一个目标性评分。生成障碍物边框信息 (包含框的位置、置信度和类别概率),完成轨道障碍物检测。
1.3 有效检测区域提取
图3
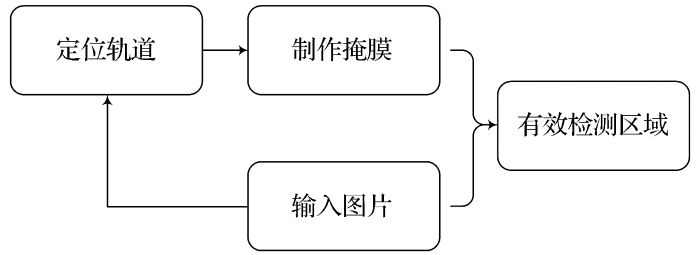
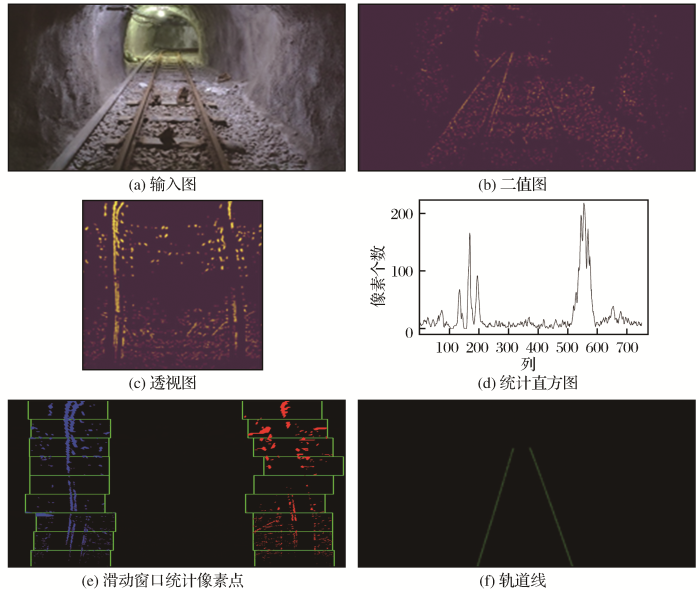
(1)定位轨道。轨道定位主要使用传统计算机技术,图4为轨道定位的几个主要步骤。①边缘检测。采用X方向的sobel算子对车载相机接收到的图像进行边缘检测[图5(a)]。选用X方向sobel算子还可以除去水平方向的一些噪点。输出带有轨道信息的二值图,如图5(b)所示。②透视变换(去畸变)。使用车载摄像机拍摄出的图像,存在畸变现象,使用OpenCV库实现透视变换过程,得到图5(c)。③统计轨道线像素点坐标信息,如图5(d)所示。首次绘制图片最下方若干行像素信息(本文统计100行就可以得到左右轨道线起始点),2个最大值即为左右轨道在图片中的起始位置。接下来图片以首次的结束点作为起始点(轨道的连续性),继续搜索,重复此过程,直到把所有的行都搜索完毕。根据图片高度设置9个窗口,所有落在窗口中的信息点,即为左右车道线的待选点,如图5(e)所示。④分别对左右车道线的待选点进行3次曲线拟合(3次函数可以较好地拟合出弯道),即可得到轨道线的曲线方程。⑤再次使用透视变换还原图像。拟合完成之后,将曲线转回到普通的视图中,得到了轨道位置,如图5(f)所示。
图4
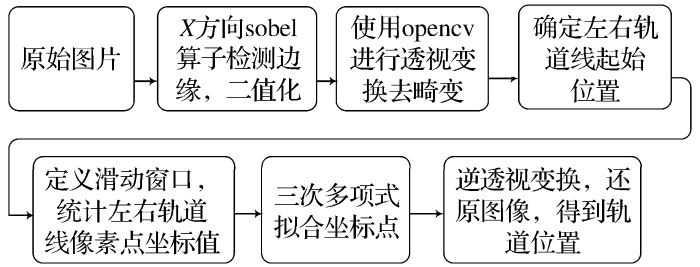
图5
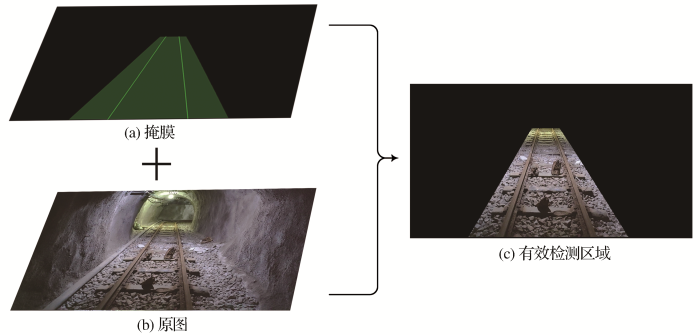
(2)制作掩膜并提取有效障碍物检测区域。定位轨道后,需要提取有效障碍物检测区域。使用“3邻域”查找法确定左右轨道线横坐标,“3邻域”查找法首先确定图片最下方左右轨道线的起始横坐标。以左侧轨道线为例(图6),有了起始点的横坐标后,以起始点的横坐标为中心,纵坐标向上移动一个像素,横坐标向左右各扩展1个像素加上正上方一个像素,一共3个像素,因为轨道线是连续的,3个像素点里面必定有一个是轨道线的横坐标,该点作为下一次的中心,重复此过程,直至检索完整条轨道线,该方法每次只检测3个像素点,极大地提高了整个方法的速度。然后左侧轨道线横坐标减去一个值,右侧轨道线横坐标加一个值,得到扩展后的左右轨道线坐标(此值可根据实际情况调整)。如图7(a)所示,将掩膜与原图叠加,就可以得到有效障碍物检测区域,如图7(c)所示,该区域包含轨道内侧和轨道两侧一定范围,区域内的障碍物都将影响电机车行驶。
图6
图7
1.4 网格化图片
图8
1.5 障碍物检测
将视频传入系统,每隔10帧截取1帧图片(视频格式为Mp4,30帧/s),图片经过预处理,得到有效检测区域,再经过设置好的网格获得距离信息,然后进入训练好的障碍物检测模型。如果检测到障碍物,则根据表2对电机车发出指令。
表2 障碍物类别距离和指令关系
Table 2
| 障碍物类别 | 不同距离下的指令 | ||
|---|---|---|---|
| >10 m | 5~10 m | <5 m | |
| 人 | 鸣笛 | 鸣笛减速 | 刹车 |
| 石块 | 减速 | 减速 | 刹车 |
| 电机车 | 鸣笛 | 鸣笛减速 | 刹车 |
2 试验与结果分析
2.1 试验环境及模型训练
本文试验数据集采集自湖北省黄石市大冶铁矿。在多种场景下拍摄视频,内容包含正常路线、前方有电机车、有掉落的大块矿石、轨道上有行人以及轨道旁有行人等场景。视频格式为Mp4,每秒30帧,每20帧提取1张图片制作数据集,最终选取1 000张包含目标障碍物的图片。将这些图片以7.0∶1.8∶1.2的比例用于训练集、验证集和测试集,每帧图片大小为1 920 pixel×1 080 pixel。软件环境:Ubuntu16.04+Darknet框架+Tensorflow框架+CUDA9.0+CUDNN7.5.0+pyhton3.6.5opencv4.0.0等。
本文对2种网络模型进行了基于数据集的对比试验。由于数据集较小,收敛效果差。借用迁移学习的思想,使用MS COCO(Lin et al,2014)数据集上预训练好的权重参数初始化Mask R-CNN模型。结合制作好的障碍物数据集对模型进行微调,获得障碍物检测模型。微调后几个重要参数设置如下:主干网络结构为resnet50,学习率为0.001,学习动量为0.9,检测置信度为0.9,权重衰减系数为0.0001,RPN的5个anchor尺度(32,64,128,256,512)。训练结果如图9所示。
图9
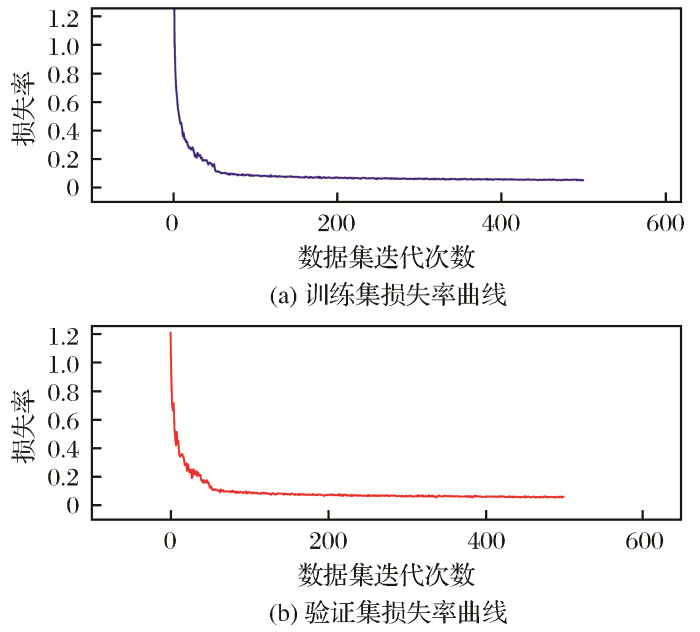
图9
训练集和验证集的损失率折线图
Fig.9
Line graph of loss rate of training set and verification set
使用在Imagenet数据集上预训练好的darknet53.conv权重文件初始化YOLOv3,结合试验数据集,经过微调得到较好的检测效果。几个重要参数设置如下:图片大小为416 pixel×416 pixel,batch=64,subdivisions=8,学习率为0.001,权重衰减系数为0.0005,学习动量为0.9。其中交IOU(Intersection-over-Union)是目标检测中使用的一个概念,是网络模型产生的候选框(Candidate Bound)与原标记框(Ground Truth Bound)的交叠率,即正常情况下它们的交集与并集的比值随着训练时间而逐渐上升。训练结果如图10所示。
图10
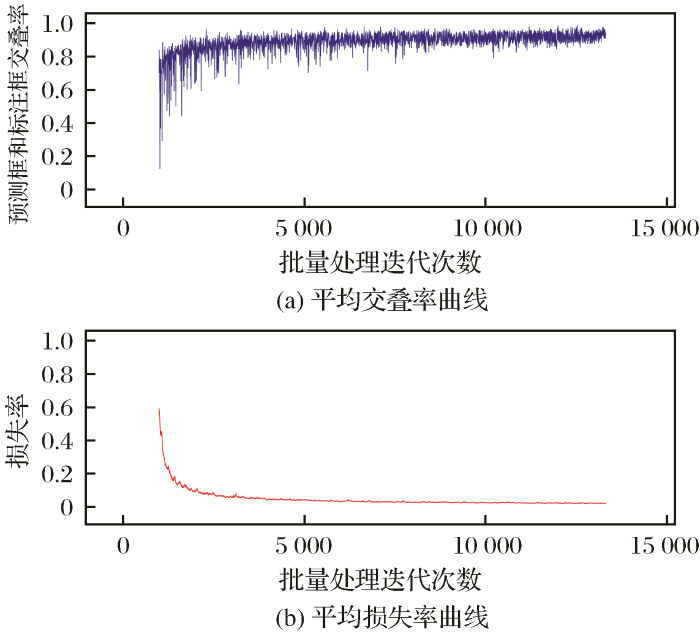
图10
训练过程平均损失率和平均交叠率曲线
Fig.10
Curves of average loss rate and average IOU during training process
2.2 评价指标和评价结果
在进行目标检测效果评价时,使用平均精度均值(Mean Average Precision,MAP)指标,具体公式为
式中:P为精确率(Precision);R为召回率(Recall)。
在计算精确率和召回率时,设模型预测框与标注框的重合率为r,当r≥0.5时,将预测结果记为正例:
式中:boxp为预测框;boxg为标注框;分子为预测框和标注框的相交面积;分母为预测框和标注框的合并面积。
图11
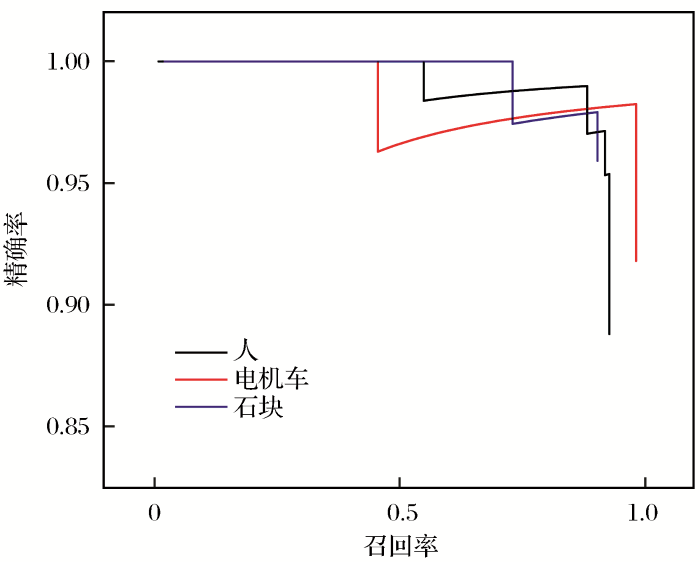
表3 障碍物检测结果
Table 3
| 障碍物类型 | 检测精确率/% |
|---|---|
| 人 | 92.3 |
| 石块 | 90.0 |
| 电机车 | 97.3 |
| 平均精度均值 | 93.2 |
| 平均单帧检测时间 | 0.02 s |
2.3 结果分析
图12
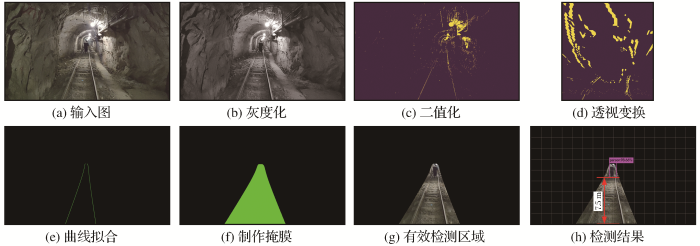
图13

在获得左右轨道线时,使用“3邻域”查找法确定左右轨道线横坐标,相对于遍历图像确定横坐标,速度有了质的提升。用遍历的方法从一张1 920 pixel×1 080 pixel的图片里面查找左右轨道线的横坐标,需要2 s左右(约200万个像素点)。而本文基于邻域法改进的“3邻域”查找法只需要0.14 s左右(仅6 000左右个像素点),节约了大量时间,这在实时监测过程中十分重要。
基于深度学习的障碍物检测方法需要大量的数据集才能达到很好的效果。前面提到的Imagenet数据集包含150万张图像,MS COCO数据集包含250万张图像。但是,个人很难甚至不可能获得如此大的数据集,同时数据集的标注也非常耗费时间。而迁移学习很好地缓解了个人在试验过程中由于数据集庞大而带来的困扰,试验使用了在Imagenet数据集上预训练好的darknet53.conv权重文件初始化YOLOv3的一些参数,然后再选取1 000张包含目标障碍物的图片在前者的基础上进行训练,试验中图片的清晰度和图片中物体的复杂度对结果都有较大的影响,相比图片中有人物重叠的情况,图片中有独立个人的识别效果明显更好,鲜艳的工作衣服也使得人物识别结果好于和地面颜色接近的石块,清晰图片的识别效果也好于模糊图片。数据集对试验的结果非常重要,同时,选择合适的处理算法和性能较高的处理机器都是必要的。
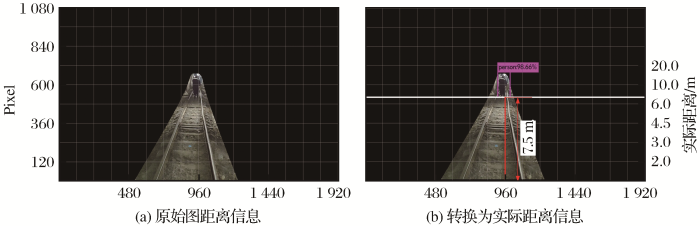
在数据集测试中,整个地下矿无人驾驶电机车障碍物智能化检测过程,从输入原图到输出检测结果仅需要0.16 s,其中提取有效检测区域需要0.14 s,障碍物检测需要0.02 s。对电机车的检测精确率较高为97.3%,而石块的颜色和地面接近导致检测精确率较低,为90.0%,MAP为93.2%。使用20张已知障碍物和实际距离的图片进行标定,测试得到的距离与实际距离的平均误差为0.042 m,说明在允许的误差范围(10 cm)内本文方法可以快速有效地得到障碍物距离电机车的距离,测试效果与真实距离在图片中的标定精度有密切关系。地下矿电机车最高行驶速度为3 m/s,拍摄的视频每秒为30帧。本文方法每隔10帧进行一次检测,处理1帧需要0.16 s,基本满足电机车行驶过程中的实时在线检测需要。
3 结论
(1)针对无人驾驶电机车发展的需求,考虑到地下矿特殊场景和当前技术手段,将传统计算机视觉技术作为图像处理的前端,提取有效检测区域,再使用YOLOv3模型对有效检测区域内的障碍物进行检测。
(2)在制作掩膜时,使用“3邻域”搜索法统计左右轨道线坐标,避免了遍历整个图片区域,能够快速得到坐标信息,并根据距离远近向外侧扩展制作掩模,从而得到有效检测区域。
(3)模型检测只针对电机车行驶区域而不是整个相机视野,提高了障碍物检测模型的准确性与实时性;提取有效检测区域后对障碍物的检测更为准确同时也更符合实际应用。同时,将图片网格化,可以快速地计算障碍物和电机车之间的距离。试验结果表明该方法有较快的处理速度(0.16 s/帧)和较高的精确率(93.2%)。
(4)计算机视觉对光较为敏感,可以针对驾驶区域安装辅助设施,在保证实时性的情况下进一步提高检测的精确率,使得无人驾驶电机车能够应用于实际作业中是该研究的最终目的。
http://www.goldsci.ac.cn/article/2021/1005-2518/1005-2518-2021-29-1-136.shtml
参考文献
ImageNet:A large-scale hierarchical image database
[C]//
Motion-based detection and tracking in 3D LiDAR scans
[C]//
Obstacle detection method in front of track based on video image
[J].
A hybrid architecture for vision-based obstacle avoidance
[J].
Deep residual learning for image recognition
[C]//
Mask R-CNN
[J].
Feature pyramid networks for object detection
[C]//
Microsoft COCO:Common objects in context
[C]//
Deep learning for generic object detection:A survey
[J].
Detection Algorithm of Railway Foreign Body Based on Depth Neural Network
[D].
Research on real-time road obstacle detection and classification algorithm using 64 line lidar
[J].
You only look once:Unified,real-time object detection
[C]//
An incremental improvement
[C]//
An obstacle detection system for automated trains
[C]//
Unstructured road detection and obstacle recognition based on machine vision
[J].
Detection of track foreign matters based on vehicle mounted forward-looking camera
[J].
Automatic obstacle detection method based on 3D lidar and depth image
[J].
Obstacle detection and tracking of unmanned vehicle based on 3D lidar
[J].
Research progress of transfer learning
[J].
基于视频图像的轨道前方障碍物检测方法
[J].
基于深度神经网络的铁路异物检测算法
[D].
采用64线激光雷达的实时道路障碍物检测与分类算法的研究
[J].
基于机器视觉的非结构化道路检测与障碍物识别方法
[J].
基于车载前视摄像机的轨道异物检测
[J].
基于三维激光雷达和深度图像的自动驾驶汽车障碍物检测方法
[J].
基于三维激光雷达的无人车障碍物检测与跟踪
[J].
迁移学习研究进展
[J].


 甘公网安备 62010202000672号
甘公网安备 62010202000672号{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}